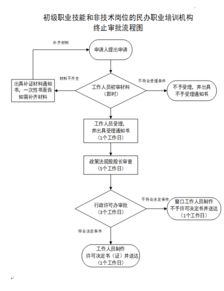
在大数据时代,GEO数据挖掘已经成为许多科研人员和工程师的必备技能。今天,就让我们跟随小明的脚步,一起探索GEO数据挖掘的基本流程与代码实现。
第一步:明确目标
作为一名初学者,小明首先意识到,任何数据分析项目都必须以明确的目标为导向。他决定从一个简单的生物信息学问题入手——分析特定基因在不同疾病状态下的表达差异。
第二步:获取数据
GEO数据库是全球最大的公共基因表达数据存储库之一。小明通过访问NCBI官网,快速定位到了一份与研究相关的GEO数据集。下载完成后,他将文件导入到本地环境进行初步检查。
第三步:数据预处理
原始数据往往需要经过清洗和格式化才能用于进一步分析。小明利用R语言中的read.csv()函数读取数据,并使用dplyr包对数据进行了筛选、去重和缺失值填补等操作。
library(dplyr)
data_clean <- data_raw %>%
filter(!is.na(expression)) %>%
select(gene_id, expression, condition)第四步:特征提取
为了更深入地理解数据,小明尝试提取了一些关键特征。例如,他计算了每个基因在不同条件下的平均表达水平,并生成了一个热图来直观展示结果。
第五步:模型构建
接下来,小明选择了一种经典的机器学习算法——支持向量机(SVM)来进行分类预测。他将数据分为训练集和测试集,并使用Python中的sklearn库完成了模型的训练与评估。
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = SVC(kernel='linear')
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)第六步:结果可视化
最后,小明通过Matplotlib绘制了一张ROC曲线,用以评估模型性能。他还制作了一份详细的报告,总结了自己的发现并与导师分享。
通过这次实践,小明不仅掌握了GEO数据挖掘的核心流程,还深刻体会到编程能力对于科学研究的重要性。如果你也想踏上这段旅程,不妨从最基础的步骤开始吧!

发表评论 取消回复