大家好,我是小李,一名数据工程师。最近在工作中遇到了一个非常有趣的技术挑战:如何使用 Apache Flink 来处理海量的数据。Flink 作为一款强大的流处理框架,支持批处理和流处理两种模式,这让我感到既兴奋又困惑。今天,我想和大家分享一下我在学习和实践中对 Flink 批模式和流模式的理解与应用。
一、初识 Flink
Flink 是一款开源的分布式流处理框架,它不仅能够处理实时流数据,还能处理批数据。最初接触 Flink 时,我被它的高性能和灵活性所吸引。相比传统的批处理框架如 Hadoop MapReduce,Flink 的流处理能力更加出色,能够在毫秒级延迟下处理海量数据。而相比其他流处理框架如 Spark Streaming,Flink 的事件时间处理机制和 Exactly-Once 语义保证了数据处理的准确性。
然而,Flink 的批模式和流模式之间的区别一直困扰着我。为了更好地理解这两种模式,我决定深入研究它们的工作原理,并通过实际项目来验证我的理解。
二、批模式 vs 流模式:核心差异
1. 批模式
批模式是指一次性处理完所有输入数据后再输出结果。Flink 的批处理功能是基于其流处理引擎构建的,因此它既可以处理有限的数据集(批数据),也可以处理无限的数据流(流数据)。在批模式下,Flink 会将整个数据集加载到内存中进行处理,处理完毕后一次性输出结果。这种方式适合处理静态数据或历史数据,例如日志分析、ETL 任务等。
2. 流模式
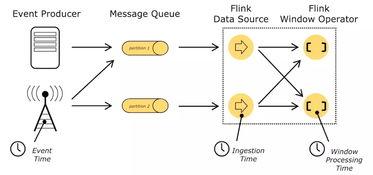
流模式则是指数据源源不断地流入系统,Flink 实时处理这些数据并立即输出结果。流处理的特点是低延迟和高吞吐量,适用于实时数据分析、监控系统、推荐系统等场景。Flink 的流处理模型基于事件驱动架构,能够处理无界数据流,并且支持事件时间处理和窗口操作,确保数据处理的准确性和一致性。
3. 统一模式
Flink 的最大亮点之一是它提供了统一的批流处理API。这意味着我们可以在同一个程序中同时使用批处理和流处理功能,而不需要编写两套不同的代码。Flink 通过 DataStream API 和 Table API 实现了这一点,使得开发者可以更灵活地应对不同场景的需求。
三、实战经验:如何选择合适的模式
在实际项目中,选择合适的处理模式至关重要。以下是我根据自己的经验总结的一些选择标准:
- 数据特性:如果数据是静态的或有限的,那么批处理模式更为合适;如果数据是动态的或无限的,那么流处理模式更适合。
- 延迟要求:如果你的应用对延迟要求不高,可以选择批处理模式;如果需要实时响应,那么流处理模式是更好的选择。
- 资源消耗:批处理模式通常需要更多的内存和计算资源,因为它需要一次性加载所有数据;而流处理模式则可以根据数据流的大小动态调整资源使用。
- 业务需求:有些业务场景需要对历史数据进行回溯分析,这时批处理模式可以更好地满足需求;而有些场景需要实时监控和响应,流处理模式则更为适用。
在我参与的一个项目中,我们需要处理来自多个传感器的实时数据,并将其与历史数据进行对比分析。经过仔细评估,我们最终选择了流处理模式为主,批处理模式为辅的混合方案。具体来说,我们使用 Flink 的流处理功能实时处理传感器数据,并通过批处理功能定期对历史数据进行回溯分析。这样的设计不仅满足了实时性要求,还提高了系统的可扩展性和灵活性。
四、遇到的挑战与解决方案
在使用 Flink 进行开发的过程中,我也遇到了一些挑战。其中最大的问题是如何处理数据的乱序问题。由于传感器数据可能会因为网络延迟等原因出现乱序,导致我们无法准确地进行事件时间处理。为了解决这个问题,我们引入了 Flink 的 Watermark 机制,它可以标记数据的时间戳,并允许我们在一定范围内容忍乱序数据。通过合理设置 Watermark 的延迟时间,我们成功解决了乱序问题,并确保了数据处理的准确性。
另一个挑战是如何优化 Flink 程序的性能。随着数据量的增加,Flink 程序的执行时间也逐渐变长。为了提高性能,我们采取了以下措施:
- 使用 RocksDB 作为状态后端,以减少内存占用并提高写入性能。
- 启用 Checkpoint 机制,定期保存程序的状态,防止因故障导致数据丢失。
- 优化并行度设置,根据集群资源和数据流量动态调整任务的并行度。
- 使用广播变量(Broadcast State)来共享全局配置,避免频繁读取外部存储。
通过这些优化措施,我们的 Flink 程序不仅能够处理更大规模的数据,而且运行效率也得到了显著提升。
五、总结与展望
通过这次项目,我对 Flink 的批模式和流模式有了更深入的理解。Flink 的强大之处在于它不仅能够高效地处理实时数据,还能灵活地应对批处理需求。无论是批处理还是流处理,Flink 都提供了一套完整的工具链和API,帮助我们轻松应对各种复杂的数据处理场景。
未来,我计划继续探索 Flink 的更多高级特性,如 SQL 支持、机器学习集成等。我相信,随着技术的不断发展,Flink 将在大数据处理领域发挥越来越重要的作用。希望我的分享能够帮助到同样在学习 Flink 的朋友们,如果有任何问题或建议,欢迎在评论区留言交流!




发表评论 取消回复