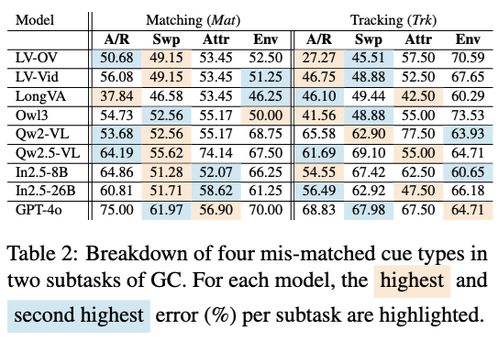
在多模态AI的浪潮中,视觉语言模型(VLMs)正以前所未有的速度发展。然而,作为一名技术爱好者,我最近深入研究了VLM²-Bench这一新基准测试后发现,这些看似强大的模型竟然在一些对人类而言“无需思考”的任务上栽了跟头。
目錄
一、VLMs的进化与局限
视觉语言模型近年来取得了显著进展,从简单的物体识别到复杂的场景理解,其能力边界不断被突破。但与此同时,一个问题逐渐浮出水面:为什么这些模型在处理复杂推理或专业场景时表现出色,却在面对一些看似简单的问题时显得力不从心?例如,当一张图片中同时包含“钥匙”和“锁孔”时,人类可以瞬间联想到它们之间的关系,而许多VLMs却无法完成这一任务。
二、VLM²-Bench:重新定义评测标准
VLM²-Bench是一种全新的基准测试方法,它不再局限于复杂知识推理或专业场景,而是将焦点转向那些对人类来说几乎是本能的任务。通过这种方法,研究人员能够更清晰地了解当前VLMs在视觉关联能力上的不足。例如,在一项实验中,模型需要根据图片中的元素推测出隐藏的关系,如“羽毛”可能与“鸟”相关,但许多模型却未能正确回答。
三、案例分析:视觉关联能力短板
为了更好地理解这一问题,我们来看几个具体的案例。在一个实验中,研究人员向模型展示了一张包含“书本”和“眼镜”的图片,并询问两者之间的关系。尽管这对人类来说显而易见,但大多数模型却给出了错误的答案。另一个例子涉及“水杯”和“桌面”,模型同样未能准确捕捉到它们之间的空间关系。这些问题表明,当前的VLMs在理解视觉元素之间的隐含联系时存在明显短板。
四、未来展望:如何弥补短板?
针对这些发现,研究者们提出了多种改进方案。首先,可以通过增加训练数据中的关联性信息来帮助模型更好地学习视觉元素之间的关系。其次,设计更加精细的注意力机制,使模型能够专注于关键细节而非表面特征。此外,结合人类反馈进行强化学习也是一种有效的途径,能够让模型逐步掌握那些“无需思考”的能力。
总之,虽然视觉语言模型已经取得了巨大进步,但在某些方面仍需进一步完善。通过不断优化评测标准和训练方法,相信未来的VLMs将能够更好地模拟人类的认知过程,为我们的生活带来更多便利。



发表评论 取消回复