在知乎平台上,有一个非常有趣且引人深思的问题:“内存划分为什么要分为堆和栈,当初设计这两个的时候分别是要解决什么问题?”。这个问题看似简单,实则涉及到计算机科学中一个极为重要的概念——内存管理。
作为一名程序员,我一直对这个问题充满好奇。今天,就让我们一起深入探讨一下,为什么在程序运行时,内存要被划分为堆(heap)和栈(stack),以及它们各自的设计初衷是什么。
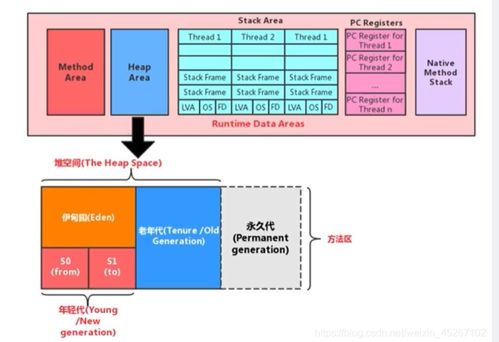
一、什么是栈?
栈是一种后进先出(LIFO, Last In First Out)的数据结构,它的操作方式类似于现实生活中的一叠盘子。你只能从最上面取下或添加新的盘子。在计算机内存中,栈用于存储函数调用时的局部变量、返回地址等信息。
栈的最大特点是高效。因为所有的操作都在栈顶进行,所以入栈和出栈的操作都非常快。然而,栈也有局限性。它只能存储固定大小的数据,并且一旦超出栈的容量,就会发生栈溢出(Stack Overflow),导致程序崩溃。
二、什么是堆?
与栈不同,堆是一个更灵活的内存区域。它允许动态分配和释放内存块。当程序需要创建一个对象或数组时,通常会使用堆来分配足够的空间。堆的灵活性使得它可以容纳任意大小的数据,但这也带来了管理上的复杂性。
由于堆上的内存分配是动态的,因此访问速度相对较慢。此外,如果程序员不小心,在堆上分配了过多的内存而没有及时释放,就会造成内存泄漏(Memory Leak),进而影响整个系统的性能。
三、为什么需要区分堆和栈?
那么,为什么我们要把内存分为这两部分呢?这其实是为了平衡效率和灵活性之间的矛盾。栈提供了快速访问的能力,但牺牲了一定的灵活性;而堆虽然可以满足更大的需求,但在使用过程中需要更加谨慎。
具体来说,栈主要用于存储临时性的、生命周期较短的数据,比如函数内部定义的变量。这些数据在函数执行完毕后就会自动消失,不会占用太多资源。相反,堆则更适合存放那些需要长时间存在的对象,如全局变量、静态变量或者大型数据结构。
四、历史背景与发展历程
早在20世纪60年代,随着编程语言的发展,人们开始意识到传统的内存管理模式已经无法满足日益复杂的程序需求。于是,一些科学家提出了将内存划分为不同区域的想法。经过不断探索和完善,最终形成了今天我们所熟知的堆和栈的概念。
早期的操作系统和编译器都面临着如何有效地管理和分配有限的物理内存这一难题。通过引入堆和栈的概念,不仅提高了程序运行的效率,还为后续的操作系统设计提供了宝贵的理论依据。
五、实际应用场景举例
为了更好地理解堆和栈的作用,我们可以看看几个具体的例子:
- C++中的指针:当你在C++代码中声明一个指针时,它实际上是指向堆上的某个位置。你可以通过new关键字在堆上分配内存,并用delete释放它。这种方式非常适合处理动态变化的数据。
- Python中的列表:Python内置的数据类型如列表(list)、字典(dict)等都是存储在堆上的。每当我们在代码中创建一个新的列表时,解释器会在堆上为其分配相应的空间。
- Java中的对象实例化:在Java中,所有类的对象都是通过new运算符在堆上创建的。这意味着每个对象都可以独立存在,并且可以在多个地方引用同一个对象。
综上所述,堆和栈作为现代计算机体系结构中的两个重要组成部分,各自承担着不同的职责。了解它们的工作原理有助于我们编写更加高效稳定的程序。希望这篇文章能够帮助大家加深对这一领域的认识,也欢迎大家在评论区分享自己的见解!



发表评论 取消回复