在编程的世界里,HashMap无疑是一个绕不开的话题。今天,让我们跟随一位热爱技术的程序员小张,一起深入探讨这个神奇的数据结构。
HashMap简介
作为一名初学者,小张起初对HashMap的理解仅仅停留在“键值对存储”这一层面。但随着项目经验的积累,他逐渐意识到,HashMap不仅仅是用来存储数据那么简单。它背后隐藏着许多精妙的设计理念和性能优化技巧。
小张常常感叹:“如果能真正掌握HashMap的源码,那我的技术水平一定会更上一层楼!”
HashMap底层实现
为了搞清楚HashMap的工作原理,小张决定从源码入手。他发现,在JDK 1.8中,HashMap采用了数组+链表+红黑树的混合结构来存储数据。这种设计不仅提高了查询效率,还兼顾了内存使用的经济性。
具体来说,当哈希冲突发生时,HashMap会将冲突的元素以链表的形式存储在同一数组索引位置。而当链表长度超过一定阈值(默认为8)时,链表会转化为红黑树,从而进一步提升查找速度。
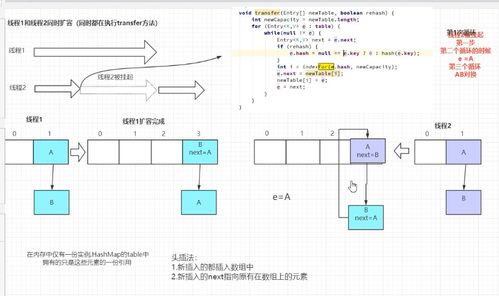
扩容机制
除了数据存储方式外,HashMap的扩容机制也是小张研究的重点之一。通过阅读源码,他了解到,当HashMap中的元素数量超过负载因子与初始容量的乘积时,就会触发扩容操作。
扩容过程并不是简单的增加数组大小,而是需要重新计算每个元素的哈希值,并将其放置到新的位置。这一步骤虽然保证了数据分布的均匀性,但也带来了不小的性能开销。
线程安全问题
尽管HashMap功能强大,但它并非线程安全的容器。这一点让小张在实际开发中吃了不少亏。例如,在多线程环境下使用HashMap可能会导致数据丢失或程序崩溃。
为了解决这个问题,小张尝试了多种方法,包括使用ConcurrentHashMap、Collections.synchronizedMap()等替代方案。最终,他总结出一套适用于不同场景的解决方案。
实践案例分享
为了让理论知识更加扎实,小张还特意编写了一个简单的测试程序,验证HashMap的各种特性。比如,他用以下代码片段展示了如何正确初始化一个HashMap:
Map<String, Integer> map = new HashMap<>(16, 0.75f);这里,16表示初始容量,0.75f则是负载因子。通过合理设置这两个参数,可以有效避免不必要的扩容操作,从而提高程序运行效率。
经过一番努力,小张终于掌握了HashMap的核心知识点,并且能够在实际工作中灵活运用。他感慨道:“学习源码的过程就像攀登一座高山,虽然艰难,但每一步都充满意义。”



发表评论 取消回复