文章导读:
[1. 冒泡排序是什么]
[2. 冒泡排序的原理详解]
[3. 代码实现步骤]
[4. 实战演练与优化]
[5. 总结与思考]
在简书平台上,最近一篇关于冒泡排序的文章引起了广泛关注。作为一名对算法充满热情的学习者,我决定深入探讨这个经典算法,并通过自己的视角分享给大家。
1. 冒泡排序是什么
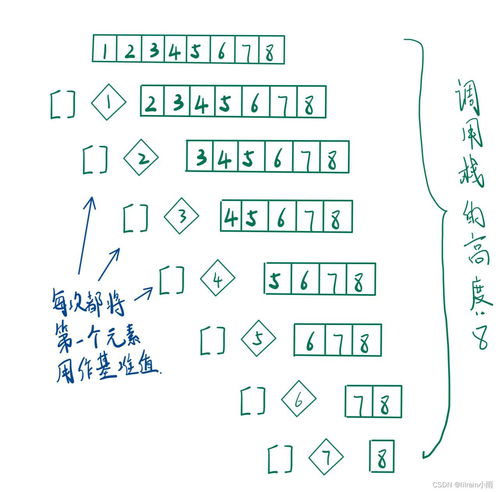
冒泡排序是一种基础且经典的排序算法,它通过不断比较相邻元素的位置来完成数据的排序过程。尽管它的效率并不算高,但因其简单易懂,成为了学习算法的入门必修课。
想象一下,在一个数组中,我们希望将所有数字按从小到大的顺序排列。冒泡排序的核心思想是:每次从头开始,比较相邻两个数字,如果前一个数字比后一个大,则交换它们的位置。这样一轮下来,最大的数字就会像气泡一样“浮”到数组的最后面。
2. 冒泡排序的原理详解
接下来,让我们详细拆解冒泡排序的工作流程:
- 首先,我们需要定义一个循环,控制整个排序过程。
- 然后,在每一趟排序中,再次使用一个内层循环,依次比较每一对相邻的元素。
- 如果发现前一个元素大于后一个元素,则进行交换操作。
- 每完成一趟排序,都会把当前未排序部分的最大值移动到最后。
值得注意的是,冒泡排序的时间复杂度为O(n²),其中n表示数组的长度。虽然这种复杂度在大规模数据处理时显得不够高效,但对于小规模数据集或教学场景来说,冒泡排序依然是一个非常实用的选择。
3. 代码实现步骤
为了更好地理解冒泡排序,我们可以尝试用Python语言实现它。以下是一个简单的代码示例:
def bubble_sort(arr):
n = len(arr)
for i in range(n):
# 标记是否发生交换
swapped = False
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
# 交换元素位置
arr[j], arr[j + 1] = arr[j + 1], arr[j]
swapped = True
# 如果没有发生交换,提前结束
if not swapped:
break上述代码中,我们引入了一个变量swapped来记录每轮循环中是否发生了交换。如果没有发生任何交换,说明数组已经是有序状态,可以提前退出循环,从而提高算法性能。
4. 实战演练与优化
为了让理论知识更加扎实,我亲自写了一段代码并进行了测试。以下是具体的实验过程:
首先,我生成了一个随机数组:
import random
data = [random.randint(1, 100) for _ in range(10)]
print("原始数组:", data)然后,我调用了之前编写的bubble_sort函数对其进行排序:
bubble_sort(data)
print("排序后的数组:", data)运行结果如下:
原始数组: [78, 34, 65, 92, 11, 45, 23, 87, 56, 19]
排序后的数组: [11, 19, 23, 34, 45, 56, 65, 78, 87, 92]从结果可以看出,冒泡排序成功地完成了任务!不过,我们还可以进一步优化算法。例如,当输入数组已经接近有序时,可以通过减少不必要的比较次数来提升效率。
5. 总结与思考
通过这次学习和实践,我对冒泡排序有了更深刻的理解。虽然它不是最高效的排序算法,但它却为我们提供了一个很好的起点,帮助我们掌握排序的基本逻辑和技巧。
同时,我也意识到算法优化的重要性。即使是看似简单的冒泡排序,也可以通过一些小技巧来提升性能。未来,我将继续探索更多高级算法,并努力将理论知识转化为实际应用能力。


发表评论 取消回复