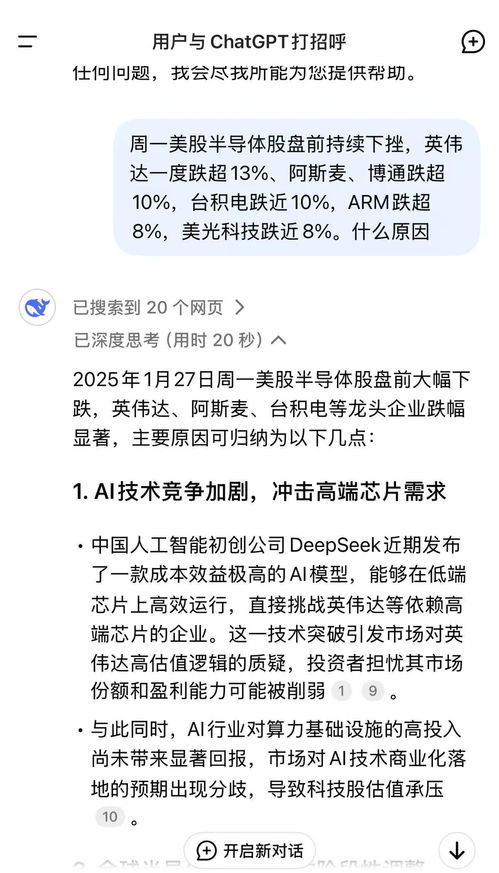
在当今人工智能迅速发展的时代,各类AI模型层出不穷。其中,一个备受瞩目的新兴力量——DeepSeek,以其独特的中文处理能力和本土知识库构建,逐渐崭露头角。然而,最近知乎上的一则热搜话题引发了广泛关注:为什么DeepSeek的回答中会说自己必须符合OpenAI的政策?
一、DeepSeek的优势与挑战
与OpenAI的GPT系列相比,DeepSeek在中文处理、本土知识库构建和特定场景应用等方面具有明显优势。例如,在涉及中国传统文化、当代社会热点等话题时,DeepSeek能够提供更准确、更接地气的回答。这种差异化优势的建立,源于研发团队对中国语言文化特征的深入理解和创新。
然而,随着DeepSeek的快速发展,也面临着一些质疑和挑战。有人认为,DeepSeek的成本之所以能如此之低,是因为它站在了巨人的肩膀上,利用了OpenAI的数据进行蒸馏训练。这种说法并非空穴来风,毕竟互联网上的数据资源丰富多样,而AI公司在获取这些数据时,确实存在一定的便利性。
二、政策合规的重要性
面对外界的质疑,DeepSeek的回答中明确表示自己必须遵循OpenAI的政策。这是因为OpenAI作为行业内的先行者,其使用协议明确规定了API客户的义务和责任。所有客户都必须遵守OpenAI的使用条款,以确保技术的恰当使用。这一点对于任何一家依赖OpenAI服务的企业来说,都是至关重要的。
具体而言,OpenAI禁止使用输出开发竞争模型,并且要求API客户不得违反其使用协议。正因如此,字节旗下部分GPT使用权限均已被OpenAI封禁。对此,字节方面给出的回应是,公司在使用OpenAI相关服务时,始终强调要遵守其使用条款。他们也在积极与OpenAI联系沟通,以澄清外部报道可能引发的误解。
三、科研规范与商业考量
除了政策合规外,围绕DeepSeek还有一种批评声音,即“不符合科研规范”。例如,有观点指出DeepSeek没有引用之前推理时间计算的相关工作,同时也缺乏与其他公司最先进模型的比较。针对这一点,有人提出OpenAI已经不再是一个纯粹的研究实验室,而应被视为一家商业公司。因此,有时它们仍会假装自己是个研究实验室,但实际上更多地关注商业利益。
这种现象不仅存在于OpenAI,其他AI公司也同样面临类似的挑战。例如,谷歌的Gemini等模型有时也会声称是竞争模型。造成这种情况的原因在于,AI公司在互联网上获取大量训练数据的过程中,不可避免地会受到各种因素的影响。为了保持竞争力,这些公司需要在科研规范和商业考量之间找到平衡点。
四、未来展望
尽管目前DeepSeek面临着诸多挑战,但其发展潜力不容小觑。通过不断优化自身的技术和服务,DeepSeek有望在未来取得更大的突破。同时,整个AI行业也需要共同努力,制定更加完善的规则和标准,以促进健康有序的发展。




发表评论 取消回复