
在当今科技飞速发展的时代,人工智能领域的竞争愈发激烈。近日,阿里巴巴集团控股发布了一款全新的人工智能模型——Qwen2.5-Max,这款升级版通义千问旗舰版模型在多项测试中得分优于Meta Platforms Inc.的Llama和DeepSeek的V3,声称其性能全球领先。
作为一位长期关注AI领域发展的观察者,我被这一消息深深吸引。从最初听到关于Qwen2.5-Max的消息开始,我就意识到这不仅仅是一次技术上的突破,更是中国AI阵营在全球舞台上的一次重要亮相。
让我们先来看看Qwen2.5-Max的具体表现吧。根据阿里云官方微信号发布的数据,在多个评测基准上,Qwen2.5-Max均取得了优异的成绩。特别是在处理长文本任务时,它能够稳定超越GPT-4o-mini,展现出强大的处理能力和高效性。不仅如此,阿里云还开源了支持100万Tokens上下文的Qwen2.5-1M模型,并推出了7B及14B两个尺寸版本,进一步增强了该模型的应用范围和技术透明度。
与此同时,市场对于Qwen2.5-Max的关注也日益增加。高盛、瑞银等国际知名金融机构纷纷发表研报,对中国AI整体性追赶表示肯定。瑞银指出,DeepSeek因其成本更低且性能较佳而备受追捧,每百万输入token成本仅为0.55美元,每百万输出token成本为2.19美元,远低于OpenAI的o1模型。然而,随着Qwen2.5-Max的出现,人们开始重新审视中国AI领域的其他参与者,如腾讯控股和百度同样在云服务领域投入大量资源,形成了多元化的竞争格局。
回顾过去几个月,DeepSeek-V3确实给全球AI界带来了不小的震撼。自去年12月以来,这款由国内大模型公司“深度求索”开发的产品以极低的训练成本实现了与顶尖模型相媲美的性能,甚至一度登顶苹果美国区免费App下载排行榜。但是,正如梁文锋在接受媒体专访时所言,如果目标是做应用,那么沿用LLaMA模型短平快上产品也是一种有效的策略。而在此次Qwen2.5-Max的发布中,我们看到了更加成熟的技术路线选择和发展方向。
值得注意的是,《自然》杂志也曾特别提到,DeepSeek R1不仅具备与OpenAI的o1模型媲美的推理能力,而且由于其开源特性,使得世界各地的研发人员都能够参与到这项伟大的事业中来。这种开放共享的精神无疑为中国AI的发展注入了新的活力。
展望未来,随着Qwen2.5-Max的成功推出,我们可以期待更多创新成果涌现。无论是阿里巴巴还是其他中国企业,在这条充满挑战与机遇的路上都将不断前行。而对于普通用户而言,这些进步最终将转化为更便捷的服务体验和更高的生活质量。



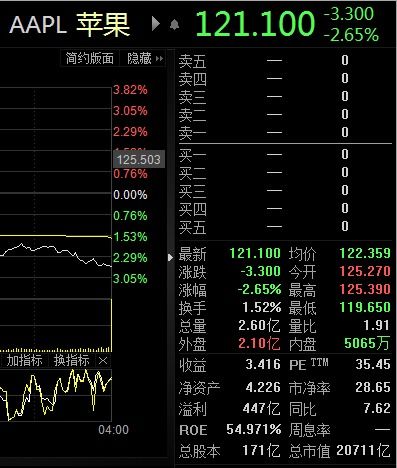
发表评论 取消回复