大家好,我是小李。作为一名数据工程师,我一直对实时数据处理有着浓厚的兴趣。最近,我开始深入学习Apache Flink,并将我的学习过程记录下来,分享给大家。今天,我想和大家分享一下我的Flink学习历程,以及我整理的Flink相关博客目录,希望能帮助更多像我一样正在学习Flink的朋友。
一、为什么选择Flink
在接触Flink之前,我也尝试过其他流处理框架,比如Storm和Spark Streaming。但随着业务需求的不断增加,我发现这些框架在处理大规模实时数据时存在一些局限性。Flink的优势在于它能够提供低延迟、高吞吐量和精确一次(exactly-once)语义的流处理能力,这正是我所需要的。
此外,Flink的社区非常活跃,文档丰富,学习资源也相对较多。最重要的是,Flink的生态系统不断完善,支持多种数据源和存储系统,如Kafka、HDFS、Elasticsearch等,这使得它在实际应用中具有很强的灵活性和扩展性。
二、Flink学习路线
学习Flink并不是一件容易的事,尤其是对于初学者来说。为了帮助大家更好地入门,我总结了一条适合大多数人的学习路线:
- 1. 了解Flink的基本概念
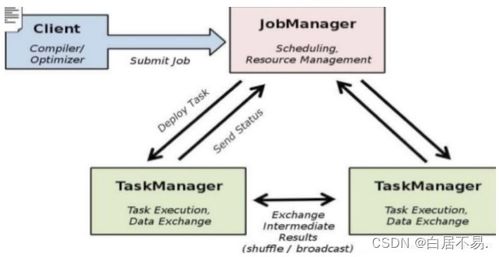
首先,你需要了解Flink的核心概念,如DataStream API、Table API、SQL、状态管理、Checkpoint等。这些概念是Flink的基础,掌握了它们,你才能更好地理解Flink的工作原理。
- 2. 搭建Flink开发环境
接下来,你需要搭建一个Flink的开发环境。你可以选择在本地安装Flink,或者使用Docker镜像来快速部署。此外,你还可以在云平台上创建一个Flink集群,进行分布式环境下的开发和测试。
- 3. 学习Flink的API
Flink提供了多种API,包括DataStream API、Table API和SQL。其中,DataStream API是最常用的API之一,适用于处理无界流数据。Table API和SQL则更适合用于批处理和流处理的结合场景。建议大家先从DataStream API入手,逐步掌握其他API。
- 4. 实战项目练习
理论学习固然重要,但实践才是检验真理的唯一标准。通过实战项目,你可以将所学的知识应用到实际场景中,解决真实的问题。例如,你可以尝试构建一个基于Flink的实时数据分析系统,处理来自Kafka的消息,分析用户行为数据,生成实时报表等。
- 5. 深入理解Flink的高级特性
当你掌握了Flink的基础知识后,可以进一步学习Flink的高级特性,如窗口操作、事件时间处理、故障恢复机制等。这些特性可以帮助你在复杂的业务场景下优化性能,提升系统的稳定性和可靠性。
三、我的Flink博客目录
为了方便大家学习,我整理了一个Flink相关的博客目录,涵盖了从基础到高级的各个知识点。以下是部分博客文章的链接:
- Flink入门指南:从零开始学习Flink
- Flink DataStream API详解:处理无界流数据
- Flink Table API与SQL:批处理与流处理的完美结合
- Flink状态管理与Checkpoint机制解析
- Flink窗口操作:时间窗口与计数窗口
- Flink故障恢复机制:确保数据处理的可靠性
- Flink与Kafka集成:构建实时数据管道
- Flink性能调优:提高系统的吞吐量与响应速度
以上是我整理的部分博客文章,每篇文章都详细介绍了Flink的某个知识点,并结合实际案例进行了讲解。如果你对某个话题感兴趣,可以点击链接查看具体内容。
四、学习心得与体会
在学习Flink的过程中,我也遇到了不少挑战。例如,Flink的状态管理和Checkpoint机制比较复杂,需要花费一定的时间去理解。另外,Flink的性能调优也是一个难点,尤其是在处理大规模数据时,如何优化系统的吞吐量和响应速度是一个值得深入研究的问题。
不过,正是这些挑战让我更加坚定了学习Flink的决心。通过不断的学习和实践,我逐渐掌握了Flink的核心技术,并能够在实际工作中应用这些知识。我相信,只要大家坚持不懈地努力,一定能够在Flink的学习道路上取得更大的进步。
五、结语
最后,我想说的是,学习Flink并不是一蹴而就的事情,它需要我们不断地积累知识,提升技能。希望我的博客目录能够为大家提供一些帮助,也希望更多的朋友能够加入到Flink的学习大军中来,一起探索这个充满魅力的实时数据处理世界。




发表评论 取消回复