大家好,我是头条X,今天我要和大家分享一个非常实用的Python模块——Pickle。在日常编程中,我们经常需要将数据保存到文件中,以便后续使用或分享。Pickle模块就是这样一个强大的工具,它可以将Python对象序列化为字节流,然后保存到文件中,也可以从文件中读取这些字节流并反序列化为Python对象。今天,我们就来详细探讨一下如何使用Pickle模块读写不同类型的文件。
一、Pickle模块简介
Pickle模块是Python标准库中的一个模块,用于实现Python对象的序列化和反序列化。序列化是指将Python对象转换为字节流,以便保存到文件或通过网络传输;反序列化则是将字节流恢复为Python对象。Pickle模块支持多种数据类型,包括但不限于列表、字典、类实例等。
二、Pickle的基本用法
1. 序列化(dump)
import pickle
# 定义一个Python对象
data = {
'name': 'Alice',
'age': 30,
'city': 'New York'
}
# 打开一个文件,以二进制写模式
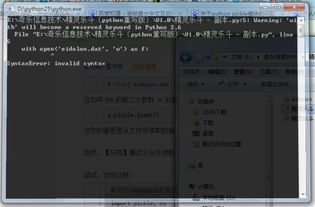
with open('data.pkl', 'wb') as file:
# 使用pickle.dump将数据写入文件
pickle.dump(data, file)2. 反序列化(load)
import pickle
# 打开一个文件,以二进制读模式
with open('data.pkl', 'rb') as file:
# 使用pickle.load从文件中读取数据
data = pickle.load(file)
print(data) # 输出: {'name': 'Alice', 'age': 30, 'city': 'New York'}三、Pickle处理不同类型的数据
1. 列表
import pickle
# 定义一个列表
my_list = [1, 2, 3, 4, 5]
# 将列表写入文件
with open('list.pkl', 'wb') as file:
pickle.dump(my_list, file)
# 从文件中读取列表
with open('list.pkl', 'rb') as file:
loaded_list = pickle.load(file)
print(loaded_list) # 输出: [1, 2, 3, 4, 5]2. 字典
import pickle
# 定义一个字典
my_dict = {'a': 1, 'b': 2, 'c': 3}
# 将字典写入文件
with open('dict.pkl', 'wb') as file:
pickle.dump(my_dict, file)
# 从文件中读取字典
with open('dict.pkl', 'rb') as file:
loaded_dict = pickle.load(file)
print(loaded_dict) # 输出: {'a': 1, 'b': 2, 'c': 3}3. 类实例
import pickle
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 创建一个Person类的实例
person = Person('Bob', 25)
# 将类实例写入文件
with open('person.pkl', 'wb') as file:
pickle.dump(person, file)
# 从文件中读取类实例
with open('person.pkl', 'rb') as file:
loaded_person = pickle.load(file)
print(loaded_person.name) # 输出: Bob
print(loaded_person.age) # 输出: 25四、Pickle的注意事项
1. 安全性问题
Pickle模块存在一定的安全性问题,因为它可以执行任意代码。因此,在处理来自不可信来源的数据时,应谨慎使用Pickle。建议使用更安全的序列化方法,如JSON。
2. 兼容性问题
Pickle生成的字节流是特定于Python的,不能被其他语言直接解析。如果需要跨语言使用,建议使用通用的序列化格式,如JSON或XML。
五、总结
通过本文的介绍,相信大家已经对Pickle模块有了更深入的了解。Pickle模块是一个非常强大且方便的工具,可以帮助我们轻松实现数据的持久化。无论是简单的列表、字典,还是复杂的类实例,Pickle都能胜任。当然,在使用过程中也需要注意一些潜在的安全性和兼容性问题。希望本文能对大家有所帮助,如果有任何疑问或建议,欢迎在评论区留言交流。

发表评论 取消回复