在简书平台上,SQL Server非聚集索引的话题热度持续攀升,作为一名热爱数据库技术的程序员,我决定深入探讨这一主题,并通过通俗易懂的语言和实际案例分享给大家。今天,就让我们一起走进SQL Server非聚集索引的世界吧!
一、什么是非聚集索引?
非聚集索引(Non-Clustered Index)是SQL Server中一种重要的索引类型。它与聚集索引不同,数据行并不按照索引键值的顺序存储,而是通过一个指针指向实际的数据行位置。这种设计使得非聚集索引非常适合用于查询频率高但更新操作较少的场景。
举个例子,我们可以把聚集索引想象成一本按字母顺序排列的电话簿,而非聚集索引则像一本书的目录页。当你需要查找某个特定内容时,可以通过目录快速定位到具体的章节,而不需要逐页翻阅。
二、非聚集索引的工作原理
为了更好地理解非聚集索引,我们需要了解它的内部结构。每个非聚集索引条目包含索引键值以及指向实际数据行的引用。当执行查询时,SQL Server会先扫描非聚集索引找到匹配的键值,然后通过引用跳转到具体的数据行。
值得注意的是,非聚集索引的性能受到其深度和宽度的影响。如果索引树过深或者单个节点包含过多数据,查询效率可能会受到影响。因此,在创建非聚集索引时,合理选择列和优化参数至关重要。
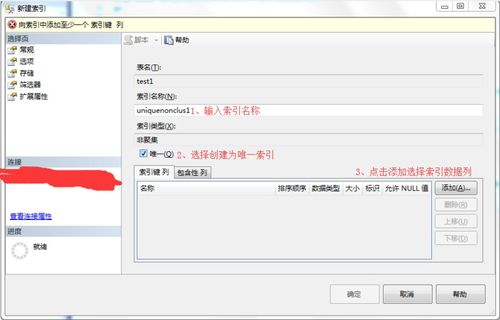
三、实战演练:如何创建和优化非聚集索引
接下来,我将通过一个简单的示例演示如何在SQL Server中创建非聚集索引并对其进行优化。
-- 创建测试表 CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, FirstName NVARCHAR(50), LastName NVARCHAR(50), Department NVARCHAR(50) ); -- 插入一些测试数据 INSERT INTO Employees VALUES (1, 'John', 'Doe', 'Sales'), (2, 'Jane', 'Smith', 'Marketing'); -- 创建非聚集索引 CREATE NONCLUSTERED INDEX IX_Employees_Department ON Employees(Department); 在这个例子中,我们为Employees表的Department列创建了一个非聚集索引。这样可以显著提高基于Department列的查询性能。
当然,仅仅创建索引还不够,我们还需要定期维护索引以确保其高效运行。例如,可以使用以下命令来重建或重新组织索引:
-- 重建索引 ALTER INDEX IX_Employees_Department ON Employees REBUILD; -- 重新组织索引 ALTER INDEX IX_Employees_Department ON Employees REORGANIZE; 四、总结与展望
通过本文的学习,相信大家对SQL Server非聚集索引有了更深入的理解。无论是理论知识还是实际操作,都为我们今后的工作提供了宝贵的参考。未来,我将继续探索数据库领域的更多奥秘,期待与大家共同进步!



发表评论 取消回复