在大数据的世界里,Hadoop无疑是一颗璀璨的明星。今天,我将和大家分享一个关于Hadoop HDFS操作的心得体会。作为一个热爱技术的人,我一直对数据存储与处理有着浓厚的兴趣。
什么是Hadoop HDFS?
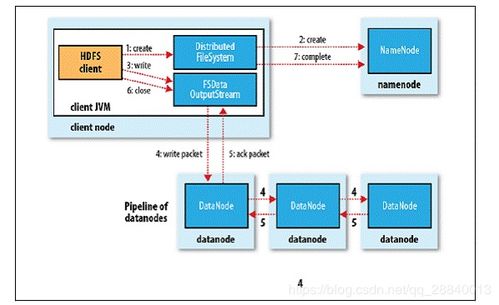
HDFS(Hadoop Distributed File System)是Hadoop的核心组件之一,它是一种分布式文件系统,专为大规模数据存储而设计。简单来说,HDFS可以将海量的数据分散存储到多个节点上,并保证数据的安全性和高可用性。
我的学习历程
最初接触HDFS时,我也曾感到迷茫。面对复杂的命令行操作和晦涩的技术文档,我甚至怀疑自己是否能掌握这项技能。但经过一段时间的学习和实践,我发现其实并没有想象中那么困难。下面,我将分享几个关键的操作步骤,帮助大家更快地入门。
一、环境搭建
首先,你需要安装Java运行环境,因为Hadoop是基于Java开发的。接着下载Hadoop的安装包并解压到指定目录。配置环境变量时,记得将Hadoop的bin目录添加到PATH中,这样就可以在任意位置执行Hadoop命令了。
二、启动HDFS服务
完成环境搭建后,接下来就是启动HDFS服务。进入Hadoop安装目录下的sbin文件夹,执行start-dfs.sh脚本即可启动NameNode和DataNode等必要进程。为了验证服务是否正常运行,可以通过浏览器访问http://localhost:9870/,如果看到HDFS的管理界面,就说明一切准备就绪。
三、常用命令操作
HDFS提供了丰富的命令行工具,用于文件的上传、下载、查看等操作。例如:
- 上传文件:hdfs dfs -put local_file_path hdfs_file_path
- 下载文件:hdfs dfs -get hdfs_file_path local_file_path
- 查看文件内容:hdfs dfs -cat hdfs_file_path
这些命令看似简单,但在实际使用中却非常实用。
四、数据块管理
HDFS的一个重要特性就是数据块的概念。默认情况下,每个文件会被分割成128MB大小的数据块,然后分布到不同的节点上存储。这种机制不仅提高了数据读写的效率,还增强了系统的容错能力。如果你需要调整数据块大小,可以在core-site.xml中修改dfs.blocksize参数。
五、故障排查
在使用过程中难免会遇到一些问题,比如无法连接到NameNode或者DataNode状态异常。此时,可以检查日志文件,通常位于logs目录下。通过分析日志信息,往往能找到问题的根源。
总结起来,HDFS虽然有一定的学习曲线,但只要掌握了基本的操作方法,就能轻松应对大多数场景。希望我的经验能够为大家提供一些帮助。未来,我还会继续深入研究Hadoop生态系统中的其他组件,如MapReduce和YARN,期待与大家一起探索大数据的无限可能。



发表评论 取消回复