作为一名数据领域的探索者,小明最近在研究SQL Server中的聚集索引时,发现这一技术背后隐藏着许多值得深挖的秘密。今天,他将带大家走进这个神秘的世界,用通俗易懂的语言,揭开聚集索引的面纱。
什么是聚集索引?
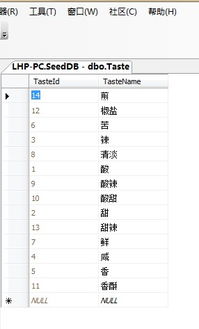
简单来说,聚集索引是一种物理存储结构,它决定了表中数据的实际存储顺序。与非聚集索引不同,聚集索引直接作用于数据本身,而不是指向数据的指针。这种特性使得查询速度更快,但插入和更新操作可能会稍微慢一些。
小明通过一个生动的例子来解释:想象一下图书馆里的书架,如果书籍按照字母顺序排列,那么查找某本书就会变得非常方便。这就是聚集索引的作用——为数据库提供一种高效的检索方式。
为什么选择聚集索引?
在实际应用中,聚集索引的优势显而易见。首先,它可以显著提高查询效率,尤其是对于范围查询和排序操作。其次,由于数据按特定顺序存储,减少了页分裂的可能性,从而提升了性能稳定性。
当然,凡事都有两面性。聚集索引也有其局限性。例如,每个表只能有一个聚集索引,因为数据只能以一种方式排序。此外,在频繁修改数据的情况下,维护成本会增加。
如何创建和优化聚集索引?
小明总结了一些实用技巧。首先,选择合适的列作为聚集索引的关键字段非常重要。通常建议使用唯一且递增的列,如主键或时间戳字段。这样可以避免页分裂问题,并确保数据插入时的高效性。
其次,定期对索引进行重组或重建也是必不可少的步骤。这有助于消除碎片化现象,保持索引的健康状态。具体操作可以通过SQL Server Management Studio(SSMS)完成,也可以编写脚本自动化执行。
最后,不要忘记监控索引的使用情况。通过分析查询计划和统计信息,可以找出哪些索引真正被利用,哪些则可能成为负担。
真实案例分享
为了验证理论知识,小明在一个电商系统中进行了实验。该系统包含一张订单表,记录了数百万条交易数据。最初,这张表没有定义任何索引,导致查询响应时间过长,用户体验极差。
经过仔细分析,小明决定在订单ID列上创建一个聚集索引。结果令人惊喜!查询速度提升了近10倍,同时其他相关操作也变得更加流畅。这一成功经验让小明深刻体会到合理设计索引的重要性。
总结与展望
通过这次深入学习,小明不仅掌握了SQL Server聚集索引的核心原理,还学会了如何将其应用于实际场景中。未来,他将继续探索更多关于数据库优化的知识,为大家带来更多有价值的分享。



发表评论 取消回复