在简书平台上,小张最近遇到了一个技术难题。作为一名资深程序员,他正在研究如何保证高并发场景下的数据一致性问题。这让他不得不深入了解分布式锁的概念以及其实现方式。
什么是分布式锁呢?简单来说,它是一种用于协调多个节点之间对共享资源访问的机制。当多个进程或线程同时运行时,为了避免冲突和数据混乱,就需要用到这种锁来确保同一时间只有一个操作能够执行成功。
一、Redis实现分布式锁
作为目前最流行的内存数据库之一,Redis凭借其高性能特点成为了很多开发者首选方案。通过SETNX命令可以轻松实现基本功能:如果键不存在,则设置该值并返回1;否则返回0表示失败。
但仅仅依靠这一条指令还不够完善,因此还需要考虑以下几个方面:
- 设置过期时间避免死锁
- 使用唯一标识符防止误删他人锁
具体代码示例如下:
SET mylock "randomValue" NX PX 30000二、Zookeeper实现分布式锁
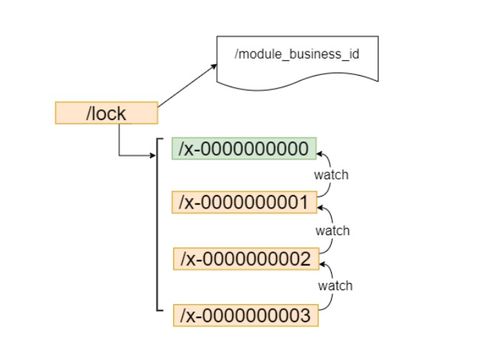
Zookeeper则提供了另一种思路——利用临时顺序节点创建全局唯一的锁对象。每个客户端都会尝试创建/locks目录下的子节点,只有第一个成功者才能获得锁使用权。
此外,还有一种更加高级的形式叫做“可重入锁”,允许同一个会话多次获取而不阻塞自身。
三、数据库表实现分布式锁
尽管效率相对较低,但在某些特定情况下仍然适用。比如可以通过UPDATE语句更新某一行记录的状态字段来模拟加锁过程。
无论采用哪种方法,都需要根据实际需求权衡利弊。对于小张而言,经过一番探索后最终选择了Redis方案,因为它不仅满足了项目性能要求,而且易于维护。
总结一下,分布式锁虽然看似复杂,但只要掌握了核心原理,并结合恰当工具和技术手段,就能够很好地解决实际问题。



发表评论 取消回复