作为一名技术爱好者,最近我在简书平台上深入研究了Flink CDC的相关内容。今天就来分享一下我的学习心得和实战经验。以下是我的个人视角总结:
什么是Flink CDC?
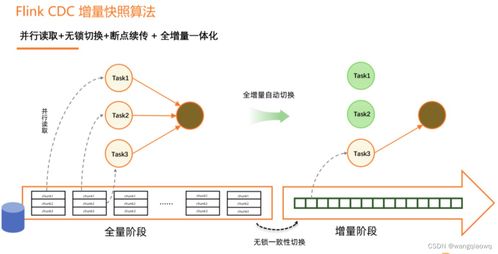
Flink CDC(Change Data Capture)是一种强大的技术,能够实时捕获数据库中的数据变更,并将这些变更以流的形式传输到其他系统中。它在大数据处理领域有着广泛的应用场景,比如实时数据分析、数据同步以及构建数据湖等。
原理解析
为了更好地理解Flink CDC的工作机制,我查阅了许多资料。简单来说,Flink CDC通过连接器监听数据库的binlog(二进制日志),从中提取增量数据变化并进行序列化处理。随后,这些数据被发送到Flink作业中进行进一步的处理和分析。整个过程高效且低延迟,非常适合需要实时性的业务场景。
我的实践之路
理论固然重要,但实践才是检验真理的唯一标准。我决定亲自尝试使用Flink CDC完成一个小型项目。目标是从MySQL数据库中捕获数据变更,并将其同步到Elasticsearch中用于全文检索。以下是具体步骤:
- 配置环境:安装Flink集群,并确保MySQL数据库启用了binlog功能。
- 编写代码:利用Flink提供的CDC连接器,编写一段简单的Java程序来读取MySQL的数据变更。
- 测试运行:启动Flink作业后,观察是否能成功捕获并同步数据。
经过多次调试,终于实现了预期效果!这让我深刻体会到Flink CDC的强大之处。
性能优化技巧
虽然Flink CDC本身已经非常优秀,但在实际应用中仍需注意一些优化点。例如:
- 调整并行度:根据任务规模合理设置Flink作业的并行度,可以有效提升吞吐量。
- 减少序列化开销:尽量选择轻量级的序列化框架,避免不必要的性能损失。
- 监控与调优:定期检查系统的各项指标,及时发现潜在问题并作出相应调整。
未来展望
随着大数据技术的不断发展,Flink CDC的应用前景愈发广阔。我相信,在不久的将来,这项技术将会为更多企业和开发者带来便利。而我也会继续探索这一领域,争取掌握更多实用技能。




发表评论 取消回复