在大数据时代,数据同步已然成为技术开发中不可或缺的一环。作为一名开发者,我最近深入研究了Canal这一开源工具,并将我的学习心得与实践经验分享给大家。
什么是Canal?
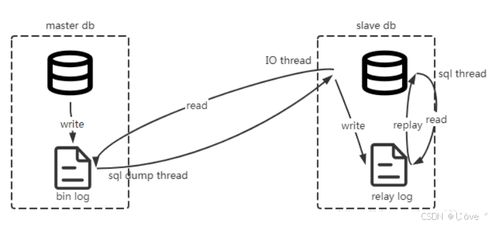
Canal是由阿里巴巴开源的一款基于数据库增量日志解析的数据订阅与分发系统。简单来说,它能够实时捕获MySQL的Binlog日志并将其转换为用户可消费的消息格式,从而实现数据的跨系统传输和同步。在实际项目中,Canal可以帮助我们解决诸如数据仓库更新、缓存同步以及分布式事务等复杂问题。
为什么选择Canal?
在我最初接触数据同步方案时,市面上已经存在多种成熟的解决方案,例如Debezium、Maxwell等。然而,经过一番对比后,我发现Canal具有以下独特优势:
- 轻量级架构:Canal的设计非常简洁,部署和维护成本较低。
- 高性能:通过高效的Binlog解析能力,Canal能够满足大规模数据同步的需求。
- 社区活跃:作为阿里巴巴开源项目的一员,Canal拥有庞大的用户群体和技术支持。
Canal的基本使用流程
为了帮助大家快速上手,我总结了一套完整的Canal使用流程:
- 环境准备:确保本地已安装MySQL,并开启Binlog功能。
- 下载与部署:访问GitHub官方仓库下载Canal源码或二进制包,按照文档完成安装配置。
- 编写客户端代码:根据业务需求,利用Canal提供的API实现数据订阅逻辑。
- 运行与调试:启动Canal服务端及客户端程序,观察日志输出以验证功能是否正常。
实践中的挑战与解决方法
尽管Canal功能强大,但在实际应用过程中难免会遇到一些棘手的问题。例如,当目标数据库表结构发生变更时,可能会导致Canal无法正确解析Binlog日志。针对这种情况,我的建议是及时更新Canal的配置文件,并重启相关服务以确保一致性。
未来展望
随着技术的不断进步,Canal也在持续迭代和完善。目前,该项目已经开始支持更多类型的数据库以及云原生架构下的部署模式。相信在未来,Canal必将在数据同步领域发挥更加重要的作用。
以上就是我对Canal的一些理解和经验分享。如果你也对这个工具感兴趣,不妨亲自尝试一下吧!


发表评论 取消回复