在简书平台上,最近有一个热搜话题引起了我的注意:“获得二级分组的键集合,也就是性别集合”。作为一个对编程和数据结构有着浓厚兴趣的人,这个话题让我感到既熟悉又好奇。于是,我决定深入探讨一下这个话题,看看它背后究竟隐藏着怎样的逻辑和应用场景。
一、什么是二级分组?
在编程中,分组是一种常见的操作,尤其是在处理大量数据时。简单来说,分组就是将数据按照某个条件进行分类。例如,我们可以根据用户的年龄、性别、地区等属性对用户数据进行分组。而二级分组则是指在已经分组的基础上,再进行一次更细致的分类。
举个例子,假设我们有一个包含用户信息的数据集,其中每个用户都有一个唯一的ID、性别和年龄。如果我们首先根据性别对用户进行分组,那么我们会得到两个大组:男性和女性。接下来,我们可以在每个大组内部再根据年龄进行分组,这就是所谓的二级分组。
二、为什么需要二级分组?
二级分组的应用场景非常广泛,尤其是在数据分析和报表生成中。通过二级分组,我们可以更清晰地了解数据的分布情况,发现潜在的趋势和规律。例如,在市场调研中,我们可以通过二级分组来分析不同性别和年龄段的消费者偏好,从而制定更有针对性的营销策略。
此外,二级分组还可以帮助我们优化数据库查询性能。当我们需要频繁查询某个特定群体的数据时,提前进行分组可以减少查询的时间复杂度,提高系统的响应速度。这对于大型企业或互联网公司来说尤为重要,因为他们每天都要处理海量的数据。
三、如何获取二级分组的键集合?
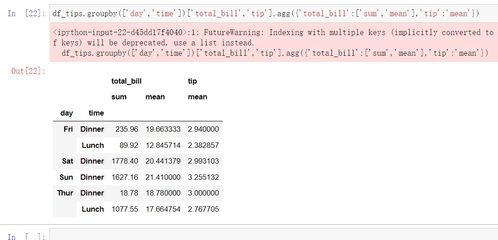
在实际编程中,获取二级分组的键集合并不是一件难事。以Python为例,我们可以使用Pandas库中的groupby()函数来实现分组操作。具体步骤如下:
- 首先,导入Pandas库:
import pandas as pd - 然后,创建一个包含用户信息的数据框(DataFrame):
data = {
'ID': [1, 2, 3, 4, 5],
'Gender': ['Male', 'Female', 'Male', 'Female', 'Other'],
'Age': [25, 30, 22, 35, 28]
}
df = pd.DataFrame(data)- 接着,使用
groupby()函数进行一级分组:
grouped_by_gender = df.groupby('Gender')- 最后,使用
groups属性获取一级分组的键集合:
gender_keys = grouped_by_gender.groups.keys()这样,我们就得到了所有性别的集合:['Male', 'Female', 'Other']。接下来,我们可以在每个性别组内再次使用groupby()函数,根据年龄进行二级分组,并获取相应的键集合。
四、二级分组的实际应用案例
为了更好地理解二级分组的应用,我决定用一个实际案例来说明。假设我正在为一家电商平台做用户行为分析。平台上有成千上万的用户,每个用户都有不同的购买记录。我想知道不同性别和年龄段的用户最喜欢购买哪些商品类别。
首先,我从数据库中提取了所有用户的购买记录,并将其加载到一个Pandas数据框中。然后,我按照性别对用户进行了分组,得到了三个大组:男性、女性和其他。接下来,我在每个大组内根据用户的年龄进行了二级分组。最后,我统计了每个二级分组中用户最常购买的商品类别,并生成了一份详细的报告。
通过这份报告,我发现了一些有趣的趋势。例如,年轻女性用户更倾向于购买美妆产品,而中年男性用户则更喜欢购买电子产品。这些发现不仅帮助平台优化了推荐算法,还为市场营销团队提供了宝贵的数据支持。
五、总结与展望
通过这次对二级分组的研究,我深刻体会到了数据结构和编程技巧的重要性。二级分组不仅仅是一个简单的技术手段,它背后蕴含着丰富的商业价值和社会意义。在未来的工作中,我将继续探索更多有趣的数据分析方法,帮助企业和个人更好地理解和利用数据。
当然,二级分组只是数据分析中的一个小环节。随着大数据时代的到来,我们将面临更多的挑战和机遇。我相信,只要我们不断学习和创新,就一定能够在数据的世界里找到属于自己的位置。




发表评论 取消回复